mirror of
https://github.com/adamhathcock/sharpcompress.git
synced 2026-07-09 02:26:47 +00:00
Slow performance of AddEntry method for big archives (more then 200K) #195
Reference in New Issue
Block a user
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Originally created by @KvanTTT on GitHub (Jun 4, 2017).
Is it possible to get rid of DoesKeyMatchExisting check for
AddAllFromDirectorymethod? It leads to non-linear time complexity.@adamhathcock commented on GitHub (Jun 4, 2017):
Might be possible to refactor how to check for duplicates but I don't see how this is a real performance problem relative to the act of actually writing/reading archives.
@KvanTTT commented on GitHub (Jun 4, 2017):
Maybe I'm wrong about performance decreasing. Need further investigation but 7zip compress big archives much faster.
@adamhathcock commented on GitHub (Jun 4, 2017):
It probably would always be faster as it's a native binary. Try ZipWriter directly if you want something faster.
@KvanTTT commented on GitHub (Jul 3, 2017):
Thanks,
ZipWriterworks much faster!@iCodeIT commented on GitHub (Oct 3, 2019):
@adamhathcock the problem with using List<> collections is that searching through them is slow, and when you try to make archives that contain 200.000 files, it gets very slow. It's an O(n^2) performance. We tried waiting more than 10minutes because of this at which point we killed the program.
If you used some sort of hash-collection instead (dictionaries comes to mind) you would have O(1) behavior, and that part of the program would run in seconds.
@adamhathcock commented on GitHub (Oct 3, 2019):
Lists are O(n) while Dictionaries would be O(log n) and then you have to be indexing/hashing by a certain value. I’m assuming you mean the Entry Key is what you want to search by.
I’m afraid you’ll need to be more specific with your scenario and possibly some code. A cached list of 200k strings still shouldn’t take ten minutes for a single match.
@adamhathcock commented on GitHub (Oct 3, 2019):
Rereading the original issue and just now thinking about trying to create an archive with a very large amount of entries like this would be slow.
A simple PR to create a hashset of the keys would be doable for creation.
@iCodeIT commented on GitHub (Oct 3, 2019):
So the problem is that each file calls AddEntry, which in turn checks if the entry already exists.
So the problem is not checking one entry - the problem is that each entry is checked against all existing entries. And that is slow. Further RebuildModifiedCollection is called for each entry, which in turn calls AddRange, which is also kind of slow.
I will see if I have time to look at this and if successful I will create a pull request.
BTW: Instead of searching the list of a specific element, with a dictionary you can use ContainsKey, which is a O(1) operation: http://people.cs.aau.dk/~normark/oop-csharp/html/notes/collections-note-time-complexity-dictionaries.html
So the for adding n entries, it will be O(n)
@iCodeIT commented on GitHub (Oct 3, 2019):
It actuall seems like it is the RebuildModifiedCollection that takes the most time as it is called for each AddEntry call. So the AddRange will add 1, then 2, then 3 etc.
For 200.000 entries, that is the a total number of 1+2+3+...+199.999+200.000 items added (the number is 20.000.100.000) and that is a problem.
I will focus on writing a fix for that instead.
@iCodeIT commented on GitHub (Oct 3, 2019):
Did a test with 45.995 files. With profiler running it took the current implementation 101.141ms to add all entries. With a minor modification it takes 4.230ms and all unit tests still pass.
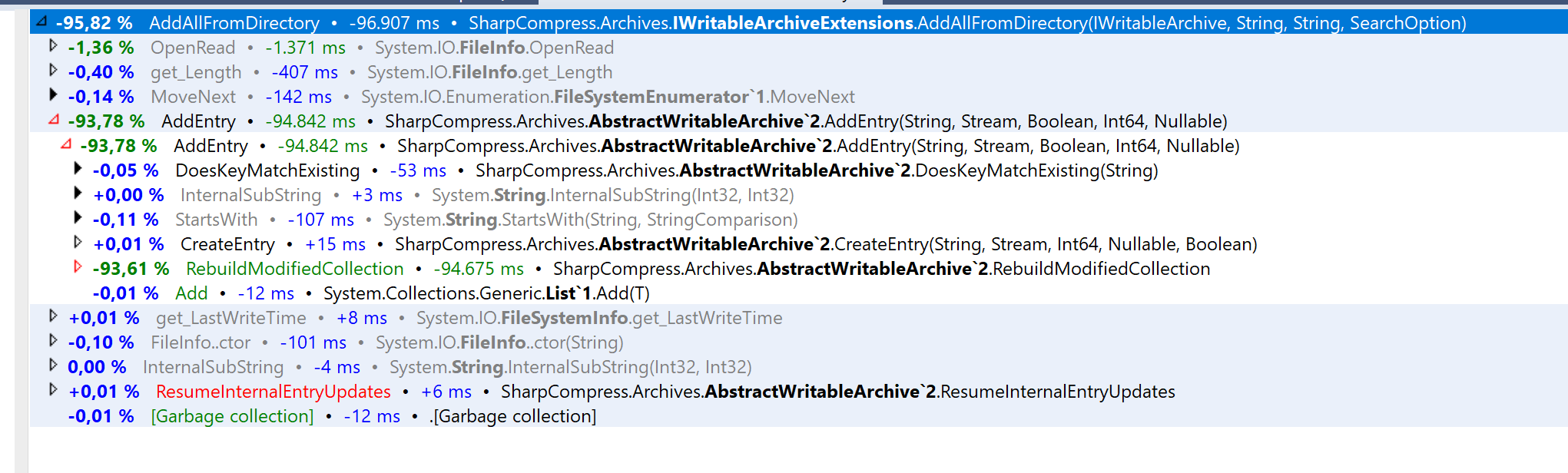
Will clean up code and make a PR later today.
This shows the profiled difference in timing.
@iCodeIT commented on GitHub (Oct 6, 2019):
Added https://github.com/adamhathcock/sharpcompress/pull/484